The Arts Council of Pakistan has a database of 20k+ attendees and full write access completely exposed. Right now.
Update: Around 2pm on February 23, the old API keys were discovered revoked and the database locked down. Some time on February 24, the database was opened up again with Row-Level Security (RLS) enabled, although some vulnerabilities were as I found still present: ones that could make it very easy to crash or upset their systems, but not any that expose their 20,000+ attendees; so I’m ending this story here. On to new projects.
And as I click publish on this post, the database is still, publicly exposed and has not been patched.
At exactly 4:32pm, 16.02.2026, I discovered something I think was absolutely insane.
Most anyone in the city’s heard of them: The Arts Council of Pakistan Karachi has a school that now offers full 4-year diploma courses and also happens to be one of the biggest organizers of events in Karachi today.
They also have a website to list their events and that website, as I discovered, is powered by a Supabase database with disabled security controls, and an API Key being used publicly from the web app. In. Raw. Text.
Not only that, but this events database is being used for their entire offline ticketing and attendee management, exposing 20,000+ people’s personal information: names, emails, phone numbers, order QRs, payment amounts, and much, much more.
If I were to draw an analogy for non-technical people, this data breach is not me finding a crevice in the wall I could use to slip a hook in and open the window. This is leaving the door to your most valuable safe wide-open, and then leaving a trail of breadcrumbs and carefully placed cardboard signs to it screaming “I’m exposed and vulnerable.”.
This is leaving the door to your most valuable safe wide-open, and then leaving a trail of breadcrumbs and carefully placed cardboard signs to it screaming “I’m exposed and vulnerable.”.
As a thought experiment, let’s examine a few possibilities of what could have happened (or perhaps has been secretly happening) because of this leak:
1. Someone could sell this personal data dump on some online anonymous forums, for idk, some bitcoin. 2. Scammers could pose as the Arts Council, building trust as they knew people’s exact details, exactly where they were on given dates down to how much they paid for each event. 3. Use it to issue themselves free tickets for events, without any pre-screening or payment: Perhaps even set up a third-party market for Arts Council events selling tickets for 100Rs each.
And what’s worse, this vulnerability couldn’t possibly be just an oversight.
Before you are allowed to disable Supabase’s default security settings, you must confirm repeatedly you are aware of the dangers and consequences of doing so, and not only that, but while it is disabled you are repeatedly sent notifications, emails, and reminders telling you to re-enable it.
Some irresponsible and reckless developer, somewhere, chose to intentionally ignore all that. The API key was also not exposed recently: I’ve found traces of it in web backups going all the way back to September 2025.
Many of own friends, regular attendees of Arts Council events’ who trusted the administration with their names, numbers, and contact information, and personal details have their data publicly exposed within, so this is personal to me.
Since I discovered this vulnerability, I have been worried sick about how to reach out to the Arts Council without alerting any bad actors, and worried whether I could even communicate to them the sensitivity of what they have wrought, because let’s be frank, someone who exposed their entire system and the personal information of 20,000+ people has to be an icon of irresponsibility and callousness.
Right now, the website and database are still exposed as they were. But I’m making this announcement publicly and alerting the Arts Council because before doing so because I’ve replaced data of the 20,000+ attendees with a non-sensitive, synthetic dataset that both protects the original attendees and doesn’t break the Arts Council’s systems.
Beyond my need to protect these innocent people (including my friends) who have been put at risk due to no fault of their own, I do not have the tools to do anything else.
I’ve also sent an email to the Arts Council at info@acpkhi.com, with a link to this article and informing them of this bug. I hope they fix this quickly before their system crashes, and I wish them the best of luck if on top of this recklessness, they have made no backups and had their financial accounting also, solely dependent on this database.
But I see an educational moment in this. The next part of this post is targeted specifically at developers, engineers, data scientists, and people interested in binary sciences… for whom I will use this breach as a practical example of what NOT to do, demonstrate the dangers of ignoring security, and break down all the attack vectors I can think of leveraging against an exposed database like this… and how to in the future, protect against them.
The vulnerability
was that the Row-Level-Security of the database was purposefully, intentionally, disabled. Supabase warns you repeatedly of the consequences before letting you do that, and those warnings were ignored. Its “security adviser” sends you notifications and follow-up emails regularly if RLS is left disabled for too long, and those warnings too, presumably, were ignored.
This was not a temporary security relaxation for whatever reason, I traced its history through the Wayback Machine, and although the site isn’t archived frequently, I was able to use the wildcard URL feature to discover some JS bundles have been saved periodically. And what did I discover? The first time this exact API Key (not even refreshed!) was seen in the bundle on September 2025: almost 5 months now.

Producing the synthetic dataset
I needed to protect the attendee’s (including my friends!) data before announcing, but also make sure I didn’t break the site. So after being inspired by some discussions with a friend, I had an interesting idea: replacing the original attendees with a synthetic dataset.
Now, any random dataset with the same schema would do, but I wanted to do a little experiment: How close could LLMs and matching statistical distribution get the synthetic to the original dataset?
And you can judge, because this is what our produced final-dataset looks like:
Since RLS was re-enabled, the synthetic dataset now loads from a CSV file instead. Download the full dataset (with QR codes) here.
btw, the sheet above is loading directly from the Arts Council’s Supabase database, now filled with our synthetic attendees. You can see exactly HOW bad the situation is.
So how did I go about producing it? I analyzed, with help from Claude ofc, the statistical distribution and patterns in the original dataset and discovered some hyper-specific and extremely niche patterns, for example:
-
Order numbers are almost always sequential, except for 18 gaps in the middle, so I simulated the original dataset by producing randomly, between 9 and 27 total gaps (+- 50% displacement).
Each gap was of random size, between 1-5 numbers long, and then there was always ONE gap which was between 30 and 70. The +-50% random displacement from the original dataset’s distributions was a general rule across patterns.
- Membership numbers were
MN-NNNN, 63% of the time.L-NNNN, 35% of the time.PM-,E-, or literalMember/M/MEMBER, 2% of the time.
That, was also matched to look like the original dataset :)
-
Attendees usually purchased tickets together in groups (of at least 2), but how big of a group was and what % of the attendees were in groups vs by themselves was heavily dependent on the event, so we calculated the per-event distributions individually and matched that in the synthetic (with +- 50% random displacement again, of course).
-
Mobiles and emails were almost always recorded for attendees except for the free events, in which case were mostly not.
But this heavy correlation didn’t just extend to events but also to specific ticket types. VIPs for example, almost never had their name, email or anything recorded. Which makes sense. How many of the attendees would have their information recorded was also matched hyper-specifically to the original dataset, per-event-per-ticket-type, then displaced by the same +-50% random displacement.
All this extremely niche statistical programming was done to produce a dataset near-unrecognizable from the original, but even this wouldn’t be enough to achieve that perfect result.
Using LLMs as a name-generator
The names in our original dataset were Pakistani, riddled with typos, spelling variations, and had characters and numbers in the emails that made them look very uniquely real.
This, was not a job for statistical rules in a Python script. For this, I had to invoke our society’s greatest accomplishment in statistical engineering: SOTA LLMs.
Using Sonnet 4.6, I first generated, at random, triplets of Pakistani names (both two-word and one), emails and mobiles, in the same format, all riddled with similar typos and patterns as the original dataset.
Since I needed to generate thousands of rows and Claude was expensive/slow… I experimented with other APIs: ChatGPT was bad, and so was GLM-5. Amusingly, they both leaned towards famous Pakistani personalites even when I made it explicity clear I didn’t want that.
GLM-5 though, did prove to give survivable results after a few rounds of prompt engineering when I generated the first 100 synthetics from Claude and used those as an example for GLM-5 to copy.
Probabilistically, the script had already calculated which fields need to be filled in vs. left empty. Once this LLM-generated CSV of triplets was ready, all I needed to do was row-by-row, fill them in.
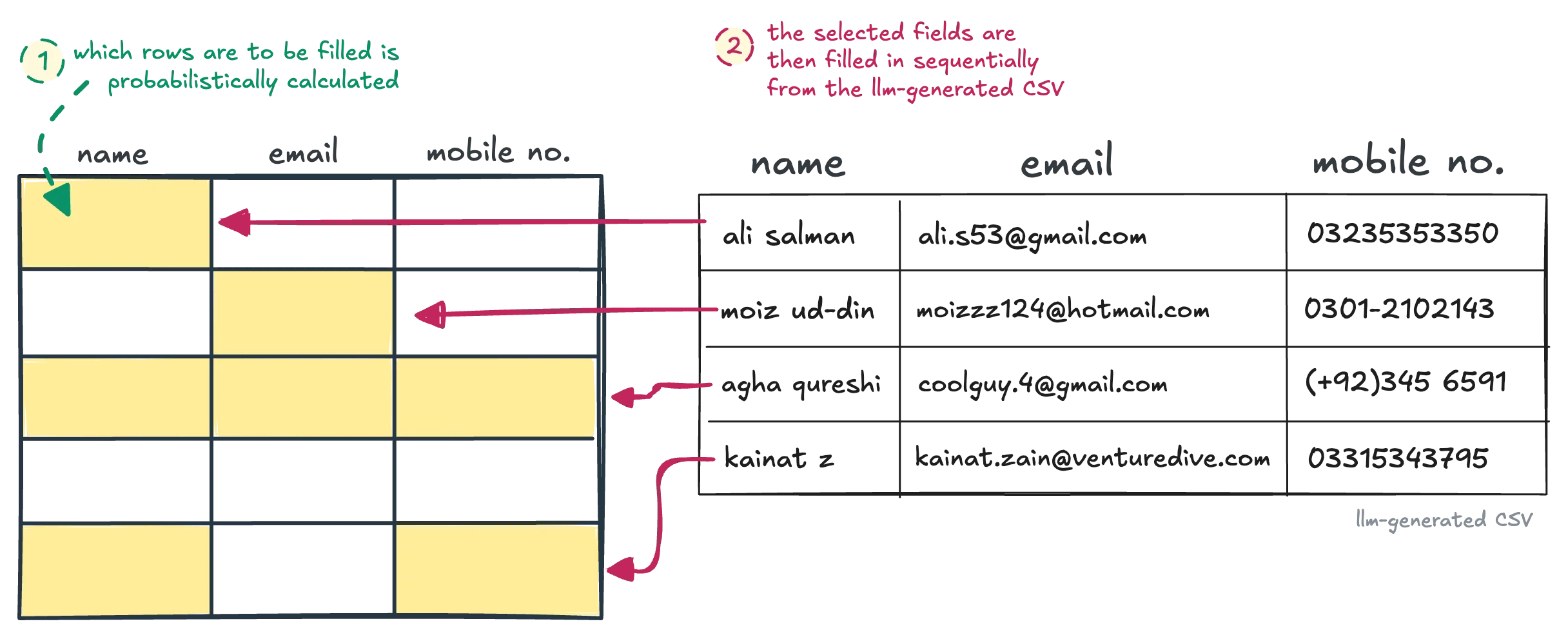
* As a final note on this topic, people who depend on AI for agentic behaviour, this is sometimes what it lacks. This idea of statistically copying patterns of the database with some randomization… even after I gave Claude the hint I wanted to replace the database and prompted it for ideas, it didn’t suggest.
Only when I explicitly mentioned it did it go “oh, that’s an amazing idea”. LLMs still very much lack in creative imagination.
QR code tickets
One of the fields was qr_codes, a base64 png image directly stored as a text field and presumably used at the ticketing counter. Decoding it revealed the pattern {order_number}-{index_in_a_group_buying_tickets_together}.
After the synthetic data was produced, I simply followed the same pattern to encode it back and produce a QR code ticket for all synthetic attendees.
Image as an attack vector
While investigating the events table to see what would be vulnerable to an XSS attack, I noticed nearly all fields were text and the app was built with Vue. Because modern PWAs protect very well against such injections by default, I looked for alternatives.
One field caught my eye: the image URL.
Now, I could probably store and fetch excessive amounts of data on load and possibly overload the database, make the arts council’s egress bill skyrocket, or prevent the site from loading for visitors, but that would be immediately obvious.
So, I set up an edge function. With a simple script that would masquerade as an image (with .jpeg extension), capture information about the visitor, and quietly redirect to the real image.
To a visitor, there would be no difference. They’re still seeing the image.
But even for anyone looking at the source: I used the original Supabase project’s id in my edge function so the URL difference was almost imperceptible.
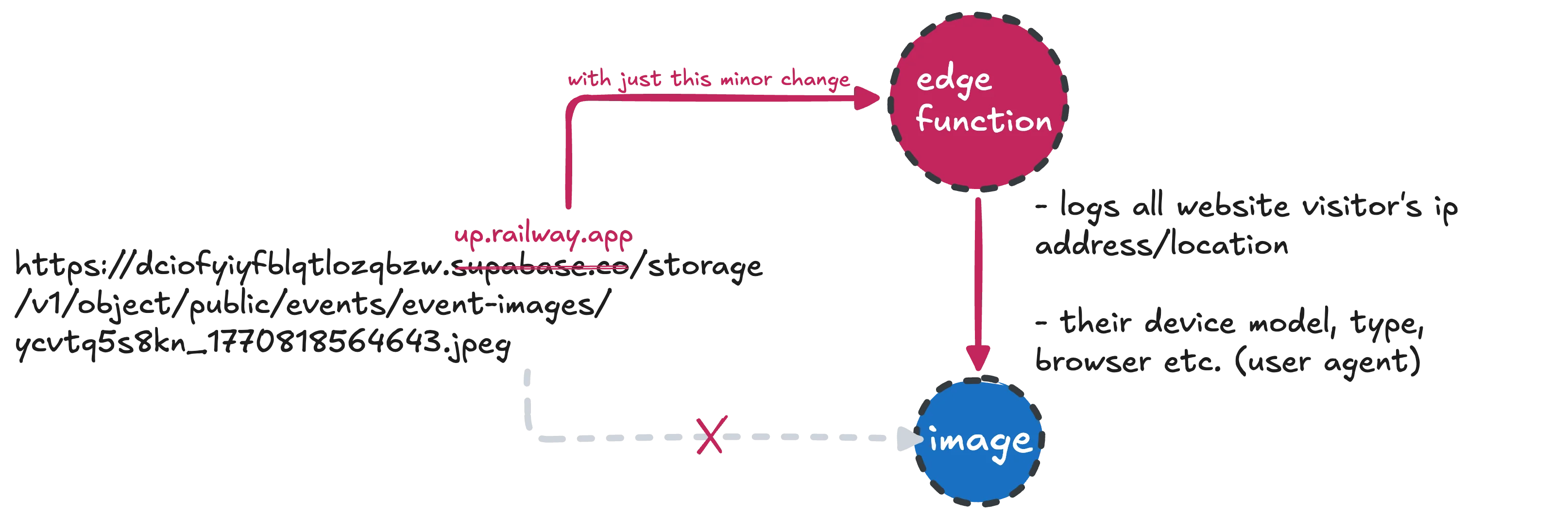
https://dciofyiyfblqtlozqbzw.supabase.co/storage/v1/object/public/events/event-images/ycvtq5s8kn_1770818564643.jpeg
➡ up.railway.app
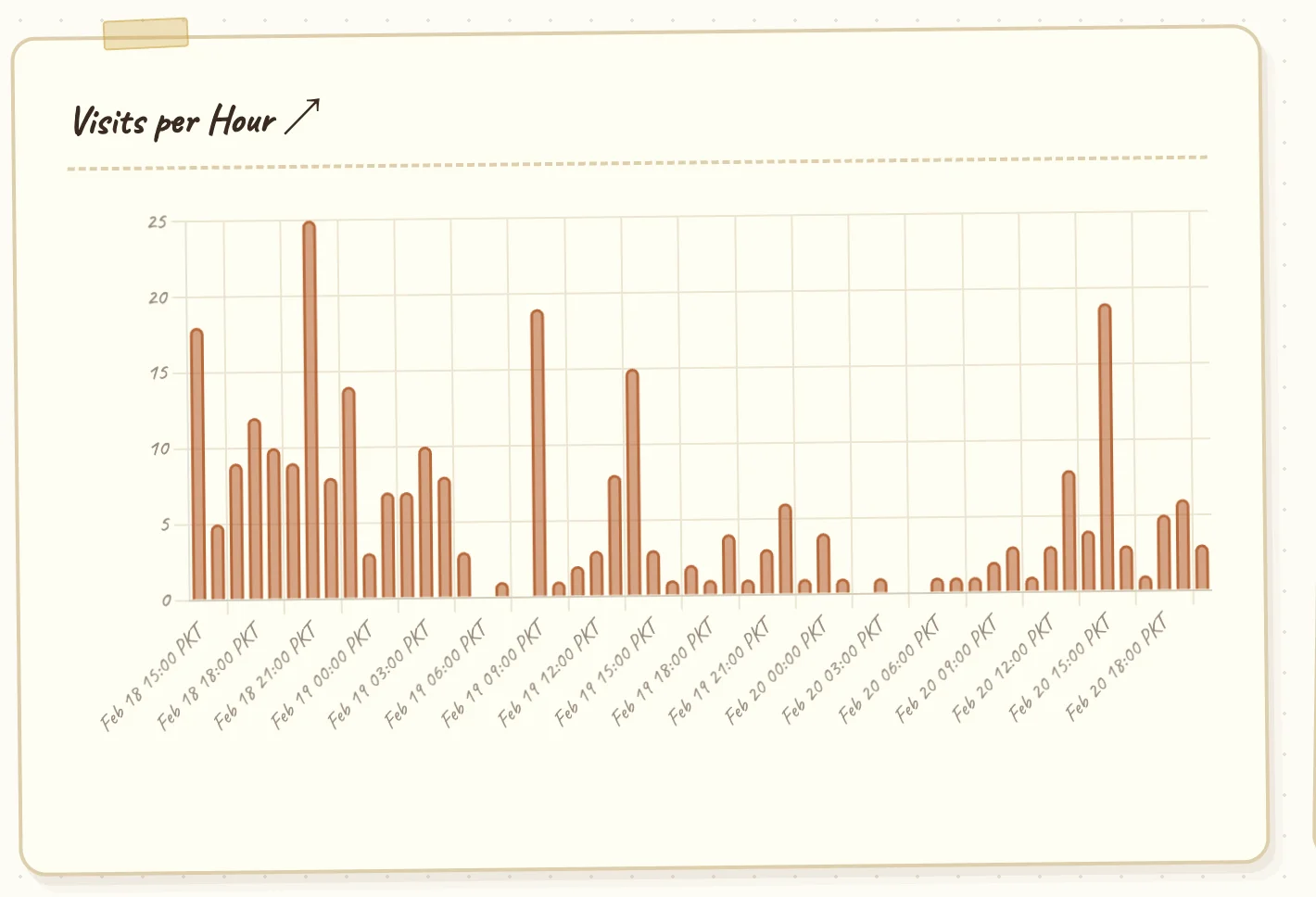
Because of just this tiny change to one image URL, I (and anyone else could) have been collecting the exact location (through IP address), time, device (user agent), and other extensive analytics on every single person who’s visited the Arts Council’s website for the past 5 days.
and an actor with bad intentions wouldn’t be interested in just researching this.